photo-what-what (pww)
photo-what-what (pww) is a small command-line utility to assist with automatically tagging image files with descriptive metadata labels/keywords/tags.
pww is little more than a glorified script which binds together the stages of the image identification process, outsourcing each stage to a more capable library or program. pww does the following:
- convert the image to a format fit for analysis (if required)
- pass the image to a user-provided program or script for analysis
- normalize the textual tags generated by the analysis script
- write the tags as metadata to the image file and/or its XMP sidecar file
Its behavior is quite configurable via a TOML configuration file, and it is suitable for calling from scripts or plugins, so it can be integrated into an image organizer like Darktable.
Note: An analysis program is required, but not provided. This tool is intended for power-users to build custom workflows. See the example below for instructions to make a basic LLM categorization script.
Warning: Do not trust this tool with images that have not been backed up! Permanent data loss may occur!
Purpose
The original purpose was to use a locally-hosted machine learning Large Language Model (LLM) to analyze every image in a large image library and tag each image with a list of identified items, to allow searching an image library for content terms like "dog" or "tree."
It is not restricted to LLM analysis, though; the analysis script can be anything that produces a comma-separated list of short strings related to an image. It could be used for tagging based on facial recognition, file or image properties, directory hierarchy, etc.
Features
-
image processing:
- direct analysis of JPG, PNG, or TIFF in 8- or 16-bit RGB or RGBA
- automatic conversion to 8-bit JPG for unsupport input formats
- for any image supported by OpenImageIO (including most RAW formats)
- automatic downscaling of images above specified dimensions
- policies for when to convert/downscale images
-
image analysis:
- dispatches image to any user-provided application or script
- optional additional arguments supported
- basic output cleanup/normalization
-
metadata:
- support for EXIF, IPTC, and XMP metadata
- optional prefix appended to each tag
- policies for whether image metadata should be replaced or appended
- policies for whether to write to image file or XMP sidecar
- can specify different fields for image vs XMP sidecar updates
Restrictions
- does not create XMP sidecar files if they don't already exist
- no support for writing non-list metadata fields
- no support for tag hierarchies
- no per-field policies
- tag normalization logic not configurable
- tags cannot contain commas
Configuration
A TOML configuration file is stored in the OS-specific user configuration directory ($XDG_CONFIG_HOME/phone-what-what/pww_config.toml on Linux). If no config file exists, a default configuration is generated and saved the first time pww is launched.
The following snippet shows the default configuration annotated with documentation:
# Full path to the application binary or script to analyze image files. The
# full path to the image is proviedd as the final argument.
#
# identifier_bin = ""
# Additional user-defined arguments passed to identifier_bin prior to the image
# path.
#
identifier_bin_args = []
# Directory where temporary converted/downscaled images should be stored.
#
# Images are automatically removed after processing.
#
# Uses OS-specific default if not provided.
#
# temp_dir = ""
# Skip files that have already been processed by pww
#
# If the pww-specific processed flag is set, which it is after pww process an
# image unless `disable_pww_tag` is enabled or another application has stripped
# it, the pww will skip processing the image again.
#
# In a pww-only workflow, this allows running pww repeatedly over a large set of
# input files and skipping the ones that were processed in previous runs.
# Unfortunately, other applications (e.g. Darktable) strip unknown tags on
# import, so this might not work in mixed workflows.
#
skip_processed = false
# Policy defining which file(s) should be updated with new metadata
#
# - DisplayOnly - Just print the tags, do not update any files
#
# - SidecarOnly - Only update XMP sidecar (error if XMP file missing). Only
# sidecar tags are used.
#
# - ImageOnly - Only update image itself. Only image tags are used.
#
# - SidecarAndImage - Update both XMP sidecar and image itself. Both sidecar
# and image tags are used.
#
# - SidecarIfPresent - Only update XMP sidecar if present, otherwise update
# image itself. Either sidecar or image tags are used.
#
# - SidecarUnlessCommonImage - Only update XMP sidecar unless image is one of a
# few common known types with good EXIF support
# (JPG, PNG, TIFF, WebP). Either -sidecar or image
# tags are used. Error if XMP file missing.
#
file_update_policy = "SidecarOnly"
# Policy defining what should be done with any pre-existing content in metadata
# fields.
#
# - Replace - Replace all existing contents (if any) with new items
#
# - Append - Append new items to existing tag contents
#
# - ReplacePrefixed - Remove existing items with the same prefix and then
# append new ones
#
tag_update_policy = "ReplacePrefixed"
# A prefix to prepend to each individual tag. In a mixed workflow, this is
# helpful to identify which tags were auto-applied
#
tag_prefix = "[ML] "
# Full hierarchy (dot-separated) of metadata fields to be updated when writing
# to an XMP sidecar (.xmp) file.
#
sidecar_tags = [
"Xmp.dc.subject",
"Xmp.lr.hierarchicalSubject",
]
# Full hierarchy (dot-separated) of metadata fields to be updated when writing
# directly to an image file.
#
image_tags = ["Iptc.Application2.Keywords"]
# The maximum dimension (height or width) to permit without conversion if
# `downscale_policy` is set to a policy with dimension restrictions.
#
# This may be useful if the identification binary is particularly slow with
# large images. Note that conversion also takes time, so there are tradeoffs.
#
# Set to 0 to disable.
#
max_dimension = 8000
# The minimum dimension (height or width) to downscale to if the image is being
# converted based on input file formats and/or `downscale_policy`.
#
# Smaller dimensions convert faster, but more information is lost and the
# identification results may suffer.
#
# Set to 0 to disable downscaling.
#
min_dimension = 768
# Set the policy for when images should be downscaled to a smaller size.
#
# - LargeOrConverted - Images that require conversion due to unsupported input
# format or images that exceed the maximum dimension are
# downscaled.
#
# - ConvertedOnly - Only images that require conversion due to unsupported input
# format are downscaled.
#
# - Large - Images that exceed the maximum dimensions are downscaled.
#
# - Never - Images are never downscaled. They are processed at the original size.
#
# - Always - Images are always downscaled. This means that all images larger
# than the minimum dimension will be converted.
#
downscale_policy = "LargeOrConverted"
# List of image formats that can be passed directly to the identifier binary
# without conversion.
#
# Supported types: Jpg, Png, Tiff
#
# All others will be converted to 8-bit RGB JPG.
#
valid_image_formats = [
"Jpg",
"Png",
]
# List of image color formats that can be passed directly to the identifier
# binary without conversion.
#
# Supported types: Rgb8, Rgba8, Rgb16, Rgba16
#
# All others will be converted to 8-bit RGB JPG.
#
valid_image_colors = [
"Rgb8",
"Rgba8",
"Rgb16",
"Rgba16",
]
# Whether photo-what-what should continue processing subsequent images after an
# error, or exit immediately. Only relevant when several images are provided at
# the command-line.
#
halt_on_error = false
# An exhaustive list of tags that are permitted to be applied.
#
# If this list is not empty, any tag returned by the identifier binary that is
# not found in this list will be discarded.
#
# Only exact matches are supported.
#
permitted_tags = []
# A list of tags that are forbidden/ignored-
#
# Any tag returned by the identifier binary that is found in this list will be
# discarded.
#
# Only exact matches are supported.
#
forbidden_tags = []
# Disables setting of the pww processed metadata field.
#
# pww sets an Xmp tag indicating it has processed a file. This can be used to
# skip reprocessing of files that have already been handled.
#
# Unfortunately, some applications (e.g. Darktable) delete unknown tags on
# import, so this isn't necessarily useful.
#
disable_pww_tag = false
Command-line arguments
The command-line requires one or more paths to image files. Some additional arguments are optional:
Usage: photo-what-what [OPTIONS] <IMAGE>...
Arguments:
<IMAGE>...
Image files to analyze and tag
Options:
-b, --identifier-bin <IDENTIFIER_BIN>
Path to program that classifies images
--temp-dir <TEMP_DIR>
Directory to store temporary files
-n, --dry-run
Do not actually write metadata to file, but print which files would have changed
-s, --skip-processed
Skip files that have already been processed by pww
--file-update-policy <FILE_UPDATE_POLICY>
Policy for which metadata should be updated
Possible values:
- display-only: Just print the tags, do not update any files
- sidecar-only: Only update XMP sidecar (error if XMP file missing). Only
sidecar tags are used
- image-only: Only update image itself. Only image tags are used
- sidecar-and-image: Update both XMP sidecar and image itself. Both sidecar and
image tags are used
- sidecar-if-present: Only update XMP sidecar if present, otherwise update image
itself. Either sidecar or image tags are used
- sidecar-unless-common-image: Only update XMP sidecar unless image is one of a few common
known types with good EXIF support (JPG, PNG, TIFF, WebP). Either sidecar or image tags
are used. Error if XMP file missing
--tag-update-policy <TAG_UPDATE_POLICY>
Policy for how changes should be made to the specified tags
Possible values:
- replace: Replace all existing contents (if any) with new items
- append: Append new items to existing tag contents
- replace-prefixed: Remove existing items with the same prefix and then append new ones
-v, --verbose
Print information about which tags are written
-d, --debug
Print extra trace information about program flow, for debugging
-e, --halt-on-error
Whether to stop processing after first error, or continue
--keep-converted
Keep converted image files in temp directory instead of removing them
--disable-pww-tag
Disables setting of the pww processed metadata field
-h, --help
Print help (see a summary with '-h')
Dependencies
- rustc + cargo (if building from source)
- libexiv2 & libgexiv2 (writing EXIF, IPTC, XMP metadata)
- libopenimageio (converting images)
- any image analysis binary/script (user-defined)
Example usage
The following snippet shows how to install and use everything necessary to perform basic automatic tagging with pww on Arch Linux, using llama.cpp's Vulkan variant (GPU-accelerated on old machines) with the LLaVa image analysis model.
This is only intended as documentation. Do not follow it blindly without understanding the commands.
# install Rust (alternatively, use rustup)
$ sudo pacman -S --needed rust
# install pww dependencies
$ sudo pacman -S --needed libgexiv2 openimageio
# install pww
$ cargo install --git git://git.trevorbentley.com/photo-what-what.git
# install ollama (to fetch model)
$ sudo pacman -S --needed ollama
# install llama.cpp-vulkan from AUR
$ wget https://aur.archlinux.org/cgit/aur.git/tree/PKGBUILD?h=llama.cpp-vulkan
$ makepkg -i PKGBUILD
# use ollama to download LLaVa model
$ ollama pull llava:7b
# make launcher script for llama.cpp-based image tagger
$ cat << EOF > llava.sh
#!/bin/bash
set -eo pipefail
if [[ $# -ne 1 ]]; then
echo "usage: $0 <image file>"
exit 1
fi
# Determine with: `ollama show llava:7b --modelfile |grep "FROM /" | cut -d" " -f2- | head -n 1`
MODEL="$HOME/.ollama/models/blobs/sha256-170370233dd5c5415250a2ecd5c71586352850729062ccef1496385647293868"
# Determine with: `ollama show llava:7b --modelfile |grep "FROM /" | cut -d" " -f2- | tail -n 1`
PARAMS="$HOME/.ollama/models/blobs/sha256-72d6f08a42f656d36b356dbe0920675899a99ce21192fd66266fb7d82ed07539"
# Change to describe desired output.
PROMPT="<image>[INST]A tag is one to two lowercase words. Select up to 8 tags listing objects in this photo. Output a maximum of 8 lowercase 1-2 word tags. Output as an unnumbered, comma separated list.[/INST]\n"
llama-llava-cli -m "$MODEL" --mmproj "$PARAMS" --image "$1" -p "$PROMPT" -ngl 200 --temp 0.1 -c 8192 -n 50 -fa 2>/dev/null | awk 'loaded && NF ; /by CLIP/{loaded=1}'
EOF
# tag one photo with pww, with debug output
$ photo-what-what --verbose --debug --identifier-bin ~/llava.sh <some image file>
# dry run tagging whole image library. Presumes an image library with existing
# .xmp sidecar files for all images.
$ find /path/to/images -exec photo-what-what --dry-run --identifier-bin ~/llava.sh {} \;
Example output
$ photo-what-what --verbose --debug ./x.jpg ./x.arw
Analyzing: ./x.jpg
- tags: [ML] christmas tree, [ML] decorations, [ML] lights, [ML] ornaments, [ML] room, [ML] shelf, [ML] table, [ML] wall
- updating file: ./x.jpg.xmp
- updated tag: Xmp.dc.subject
- updated tag: Xmp.lr.hierarchicalSubject
- saved: ./x.jpg.xmp
Analyzing: ./x.arw
- conversion required: invalid format
- converting to rgb8 jpg
- converted to: /tmp/pww-TAUIBtCZ.jpg
- tags: [ML] christmas tree, [ML] decorations, [ML] lights, [ML] ornaments, [ML] room, [ML] shelf, [ML] table, [ML] wall
- updating file: ./x.arw.xmp
- updated tag: Xmp.dc.subject
- updated tag: Xmp.lr.hierarchicalSubject
- saved: ./x.arw.xmp
Development status
This is a one-off, unsupported program that will not receive active development. Feel free to make bug reports and requests. Bugs will maybe be fixed, new features will probably not be added.
It has only been tested in Linux, but all dependencies are cross-platform so it presumably works elsewhere.
You should absolutely not use this tool on photos that have not been backed up! It is mostly untested and entirely unwarranted and unguaranteed and it should not be trusted.
Darktable Plugin
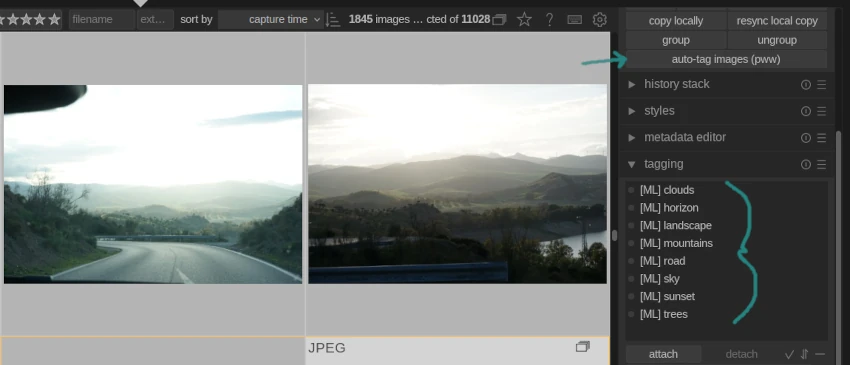
A minimal Lua plugin for Darktable is included, darktable/photo-what-what.lua.
The plugin adds a single "auto-tag images (pww)" button to the "Action on Selection" menu in the Lightroom view. Select one or more images, click auto-tag, and the process of tagging runs in the background.
If necessary, paths to pww itself and the desired identifier binary/script can be configured in Darkroom's settings under the "Lua options" tab. This is unnecessary if the photo-what-what binary is in your path and the identifier binary is specified in your pww_config.toml.
Install it via Darktable's extremely user-unfriendly standard method: copy it to ~/.config/darktable/lua/contrib/photo-what-what.lua, manually append require "contrib/photo-what-what" to ~/.config/darktable/luarc, and restart Darktable. (Paths may be different, depending on OS and configuration.)
Related solutions
At the time this was written (early 2025), I could not find any free solutions for local automatic content tagging with AI/ML/DL/LLMs in Linux that were compatible with my photo workflow.
Some existing image content tagging/search solutions:
- LlavaImageTagger (GUI-only, I think)
- digiKam "Auto-Tags Assignment" (GUI-only, digiKam namespace)
- PhotoPrism (web-based, unknown tag compatibility)
- Photonix (web-based, unknown tag compatibility)
- Apple "Visual Look Up" for iPhones (cloud-based, tags secret)
- Google Photos unnamed(?) content search (cloud-based, tags secret)
- Lightroom Desktop "Sensei" (cloud-based, tags secret)
- LrTag (lightroom plugin, paid, Windows)
- MyKeyworder (lightroom plugin, paid, Windows)
- Excire Foto (paid, Windows)
- lrc-ai-assistant (lightroom plugin, cloud-based, Windows)
- AnyVision (lightroom plugin, cloud-based, Windows)
There are many others, probably better and more complete than pww.
Notes on image metadata
Note: I have no background in image metadata standards or implementation.
Image metadata is recorded according to one of three common standards: EXIF, IPTC, or XMP. EXIF, probably the most famous, is the oldest and most restrictive. XMP is the newest and preferred, but quite complex. IPTC is not often spoken about directly, but people often mean IPTC when they say EXIF.
EXIF has no standard support for tags/keywords/labels, the thing that pww is built for. IPTC added a Keywords metadata field, and when tools claim they are writing EXIF keywords, they are nearly always writing to this IPTC field. IPTC keywords are well-supported by tools.
Both EXIF and IPTC metadata are stored inside the original image file. This conveniently means any metadata moves with the image if it is copied or uploaded. This inconvieniently means that any metadata update requires rewriting the entire image file, which could be very large. Metadata update failures can permanently corrupt the original image.
XMP is an XML-based metadata format which can be stored directly in the image file, or in a separate metadata-only file called an XMP sidecar file. Storing in a separate file is preferred for large library management, and especially for RAW files, because it doesn't require modifying the original source images.
All three formats use namespacing to group metadata fields, though differently. For instance, IPTC keywords are stored in the "Iptc.Application2.Keywords" field, Lightroom stores keywords in "Xmp.lr.hierarchicalSubject", and digiKam stores them in "Xmp.digiKam.TagsList". Metadata fields are stored in different formats and character encodings depending on the standard and namespace.
For maximum compatibility across applications, it is necessary to read from or write to several different metadata fields. Every application differs in which fields it reads/writes, and how it handles it when several fields are set.
Specifically for keywords, the following fields are most important for broad compatibility:
- Iptc.Application2.Keywords
- Xmp.dc.subject
- Xmp.lr.hierarchicalSubject
Notes on LLM tagging
Note: I have no background in AI or LLMs, and this is all voodoo magic.
Large language models (LLMs) are glorified spreadsheets that "predict" the next word of output based on a bunch of statistical weights and the previous words it saw or output, with a healthy dose of randomness tossed in. Amazingly, this is sufficient to make them appear smart. They most certainly are not.
LLMs are trained on certain input types. LLaVa, a model for image analysis, uses the Contrastive Language-Image Pre-Training (CLIP) neural network. (Whatever any of that means.) While text-based models seem to operate on a single model file, image-based models are "multimodal" and split into a base model and a "multimodal projector," which means frontend clients require some specific support for image inputs.
Downloading and using models locally is fully possible, with various frontends available to assist with it such as ollama and llama.cpp. Performance can be greatly optimized with GPU assistance. Different clients support different GPUs in different ways and with different degrees of success. At the time of writing, llama.cpp has better support for older GPUs with its optional Vulkan-based build. The GPU dependency means that it is difficult/expensive to parallelize LLM-based tagging, since it is hardware-bound.
Models come in different sizes, based on the number of training parameters. The LLaVa is available in 7b, 13b, and 34b versions, for instance. Large variants require considerably more disk space and more processing time, but are expected to return more accurate results. The tradeoffs are complicated.
There must be some mechanism for converting an image file into the format required by the model. llama.cpp uses the STB image library to do so, which means it effectively works with any image file that STB can load. I do not know if the input image format affects the LLM behavior in any way.
Each model is trained on some specific prompt format, which they aren't particularly great about documenting. Some clients automatically format a string into the prompt for you, others expect you to provide a valid raw prompt. ollama show <MODEL> --modelfile is helpful to get some feedback about the raw prompt format for a specific model. If you get the format wrong, the LLM will probably still produce a response, but it might be very low-quality.
Talking to an LLM is like talking to somebody suffering from advancing senility. It often answers your question, often in the way you wish, but sometimes it goes off on a long, bizarre tangent. Using a text prompt to tell the LLM what format you desire, like a comma-separated list of strings, only works most of the time, but sometimes it will output in bullet points or numbered list or paragraph form anyway. Some LLM frontends support forcing the output into a known format, with differing implementations for how they accomplish it and different degrees of success.
Clients also have options to configure how much output an LLM is permitted to generate before it is cut off. For tagging, this should probably be set to a low limit. Setting a limit in the prompt (ex: "identify 5 objects in this image") works sometimes, but does not stop it from sometimes outputting a 4,000 word essay.
LLMs react to prompts, but don't actually understand them and don't fully follow them. Attempting to control the output with orders like "output must contain no more than 5 tags" or "tags must be lowercase english words" or "each tag must be unique" cause the output to trend in the direction you wish, but do not fully restrict it. However, each order tends to get less weight as a prompt gets longer and longer, so the more rules you specify the less likely it is to follow any specific one of them. Sometimes repeating them several times helps, sometimes not. Sometimes specific keywords work very well, sometimes not. All of it is dependent on the model you are using, statistics, and random chance.
Realistically, you have to either provide a fixed list of permitted terms, or accept that sometimes the model is going to return bizarre and undesireable tags.
LLM output is much more trustworthy when answering a specific boolean question ("Does this image contain a dog?") than an open-ended one ("What objects does this image contain?"). Both questions take about the same amount of compute time, though, and you probably don't have enough GPUs to afford asking an LLM dozens of independent questions about each of your photos.
When asking for a list of tags, the output definitely needs some amount of post-processing; at the very least, deduplication, as LLMs happily return the same word 100 times in a row.